上市公司定期报告爬取
在经济政策不确定性与企业数据资产配置这篇论文中, 我们利用构建的数据资产术语词典, 统计了上市公司年报中数据资产相关术语的词频, 据此构造了一个度量数据资产配置水平的指标。
在这里我将展示从巨潮资讯网爬取上市公司定期报告的代码,我为这套代码额外添加了用户交互, 读者可以直接使用我的代码进行爬取,也可以在此基础上进行修改。

Python代码
巨潮资讯的数据接口并不复杂,因此在这里我不打算介绍抓包分析的过程, 感兴趣的读者可以直接从我的代码中了解与数据接口相关的信息或与我取得联系。 在这里我主要介绍代码的功能和使用方法。
首先,我在下方贴出我的代码,然后再对其进行介绍:
Tip
在运行代码前你需要安装requests和tqdm这两个第三方库
from requests import post, get
from json import loads
import os
from tqdm import tqdm
from re import match
class fin_report_crawler(object):
def __init__(self):
self.request_orgId_url = "http://www.cninfo.com.cn/new/information/topSearch/query"
self.request_fileLink_url = "http://www.cninfo.com.cn/new/hisAnnouncement/query"
self.request_pdf_url = "http://static.cninfo.com.cn/"
self.select_record = None
self.report_type = {
"年报" : "category_ndbg_szsh;",
"半年报" : "category_bndbg_szsh;",
"一季报" : "category_yjdbg_szsh;",
"三季报" : "category_sjdbg_szsh;",
}
while not self.select_record:
keyword = input("请输入公司简称或股票代码,按回车确认:")
r_init = post(self.request_orgId_url,
data = {
"keyWord" : keyword
})
json_init = loads(r_init.text)
if len(json_init) > 1:
for index, item in enumerate(json_init):
print("{0: <3}{1:{3:}<8}{2:{3:}<8}".format(index, item['zwjc'], item['code'], chr(12288)))
select_no = int(input("查询结果不唯一,请输入序号并按回车进行选择:"))
self.select_record = json_init[select_no]
print("-"*10 + "选择的是:" + "-"*10)
print("{0: <3}{1:{3:}<8}{2:{3:}<8}".format(select_no, self.select_record['zwjc'], self.select_record['code'], chr(12288)))
elif len(json_init) == 1:
self.select_record = json_init[0]
print("-"*10 + "查询到的公司是:" + "-"*10)
print("{0:{2:}<8}{1:{2:}<8}".format(self.select_record['zwjc'], self.select_record['code'], chr(12288)))
else:
print("未找到相关公司,请重新输入")
def query_reports(self):
print("-" * 10 + "定期报告查询" + "-" * 10)
# 报表类型
for index,item in enumerate(self.report_type.items()):
print("{0: <3}{1:{2:}<8}".format(index, item[0], chr(12288)))
input_query_type = input("请输入需要查询报表类型的序号(如需查询多种则输入多个序号,如0123),按回车确认:")
print("-" * 10 + "选择的类型是" + "-" * 10)
query_type = ""
for num in input_query_type:
type_name,type_code = list(self.report_type.items())[int(num)]
print(type_name)
query_type += type_code
# 查询时间段
query_period = None
while not query_period:
query_start_date = input("\n请输入查询的开始日期(报告发布日期,非财务年度),按回车确认(格式YYYY-MM-DD,如2022-07-22):")
query_end_date = input("请输入查询的结束日期(报告发布日期,非财务年度),按回车确认(格式YYYY-MM-DD,如2022-07-22):")
if match("\d{4}-\d{2}-\d{2}", query_start_date) and match("\d{4}-\d{2}-\d{2}", query_end_date):
query_period = query_start_date + "~" + query_end_date
else:
print("时间格式不正确,请重新输入")
print("\n正在获取数据...")
# 第一次post所用data
query_post_data = {'stock' : self.select_record['code'] + ',' + self.select_record['orgId'],
'seDate' : query_period,
'category' : query_type,
'pageSize' : 30,
'pageNum' : 1,
'tabName' : 'fulltext'
}
r_report_query = post(self.request_fileLink_url, data = query_post_data)
total_record = [] # 存放所有记录的列表
# 解析数据
json_report_query = loads(r_report_query.text)
total_record_num = json_report_query["totalRecordNum"] # 所有记录条数
total_record += json_report_query["announcements"] # 将第一页的记录添加进列表
while len(total_record) < total_record_num: # 如果第一页没有返回全部记录,则继续请求
query_post_data['pageNum'] = query_post_data['pageNum'] + 1
r_report_query = post(self.request_fileLink_url, data = query_post_data)
json_report_query = loads(r_report_query.text)
total_record += json_report_query["announcements"]
assert len(total_record) == total_record_num, '错误:数据获取不完整!'
total_record = [record for record in total_record if record["adjunctType"] == 'PDF']
print("-" * 15 + f'共查询到{len(total_record)}条数据' + '-' * 15)
# 打印所有获取的记录
for num, record in enumerate(total_record):
print("{0:{2:}<4}{1:{2:}<40}".format(num+1, record["announcementTitle"], chr(12288)))
return total_record
def download_reports(self, records_ls):
print("正在下载:")
save_folder = "./下载_巨潮资讯/"
if not os.path.exists(save_folder):
os.mkdir(save_folder)
save_path = save_folder + self.select_record["zwjc"] + self.select_record["code"]
if not os.path.exists(save_path):
os.mkdir(save_path)
for record in tqdm(records_ls):
full_url = self.request_pdf_url + record["adjunctUrl"]
file_name = record["announcementTitle"] + ".pdf"
r_pdf = get(full_url)
pdf_content = r_pdf.content
with open(save_path +"/"+file_name, 'wb') as f:
f.write(pdf_content)
print("全部下载完成!")
def query_and_download(self):
while True:
total_record = self.query_reports()
print("\n是否下载以上列出文件?")
flag_download = None
while not flag_download:
flag_download = input("Y/N:")
if flag_download == 'Y' or flag_download == 'y':
self.download_reports(total_record)
elif flag_download == 'N' or flag_download == 'n':
print("\n***选择不进行下载***")
else:
print("输入错误,请输入Y或N")
flag_download = None
input("如需继续查询[{}]的相关报告请按回车,结束请直接关闭窗口,查询其他公司请重新打开程序".format(self.select_record["zwjc"] + self.select_record["code"]))
我将代码的全部功能封装到了一个类当中,你可以将该类进行实例化,
然后调用query_and_download方法来运行它:
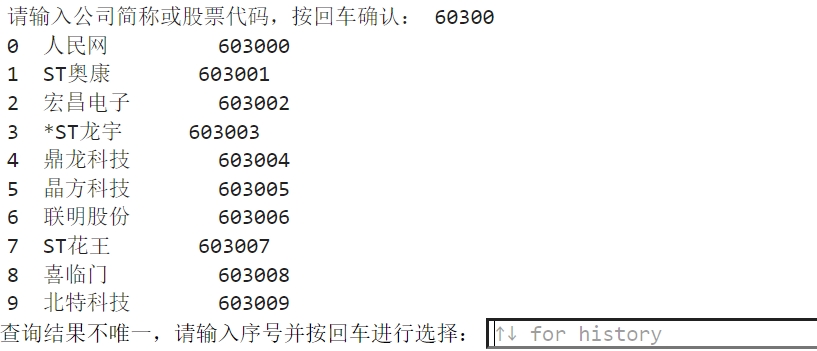
在输入框中输入想要查找的公司年报的代码后,会向服务器进行一次代码查询,返回匹配的代码, 通过输入序号可以选择正确的上市公司
接着在输入框中输入想要查询的定期报告类型

再输入查询的起始时间,然后会向服务器再次进行查询,并列出所有查询到的年报结果
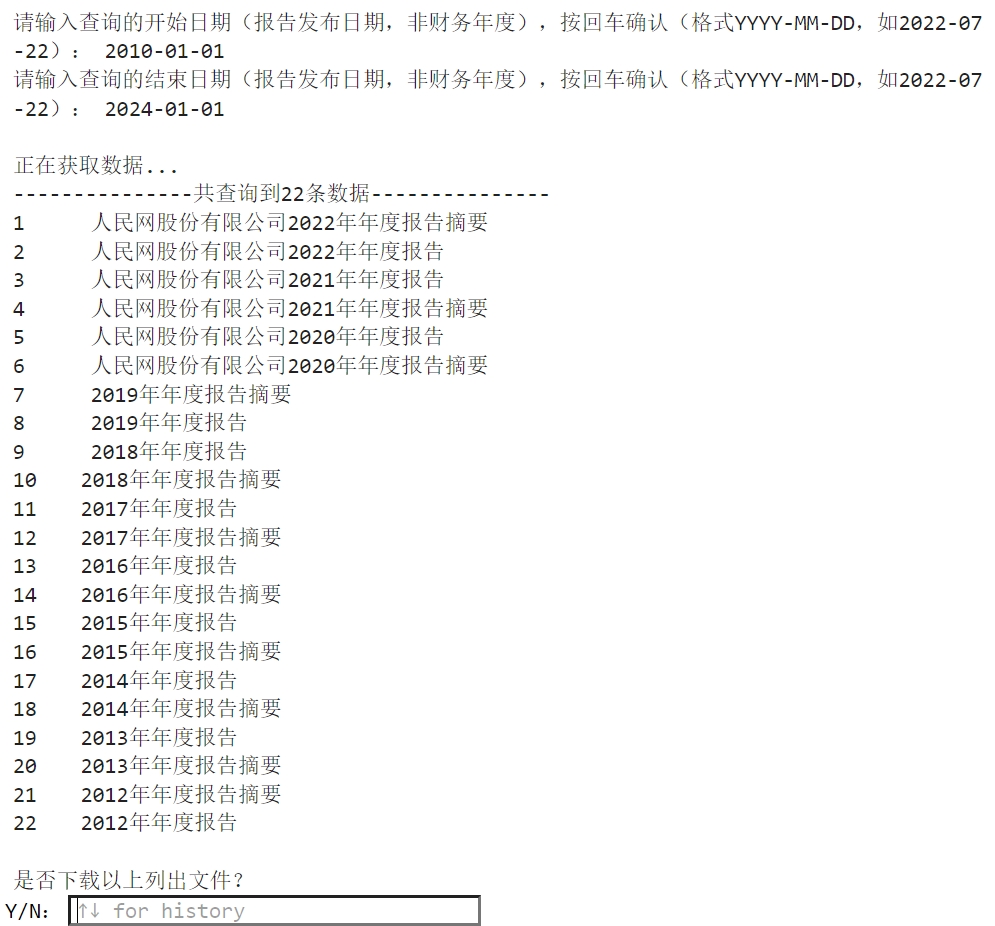
确认下载后,会向服务器拉取pdf字节流, 然后保存到此python脚本运行的工作目录下的“下载_巨潮资讯”目录中。 考虑到下载时间可能较长,我在代码中添加了进度条

下载结束后可以在对应的文件夹中找到pdf文件, 我直接采用了服务器响应的原始pdf文件名,读者可以修改代码使得pdf文件名称统一