酷云-剧集播出时间数据
酷云提供了国内热门电视剧的收视数据,包括电视频道的收视率和网络平台的播放市占数据。这篇文章介绍如何爬取电视剧的准确播出时间。
| 日期 | 时间 | 平台 | 收视排名 | 平均收视 | 播出集数 |
|---|---|---|---|---|---|
| 2023/12/27 | 19:30 | CCTV8 | 1 | 0.019984 | ep1,ep2 |
| 2023/12/28 | 19:30 | CCTV8 | 1 | 0.018559 | ep3,ep4 |
| 2023/12/29 | 19:30 | CCTV8 | 1 | 0.017299 | ep5,ep6 |
| ... | ... | ... | ... | ... | ... |
数据接口
进入酷云官网,以撰写本文时热榜第一的《与凤行》为例,进入到其节目页面。在趋势表现标签下,历史收视部分的实时标签下有该电视剧每天在各个电视频道的播出情况线图。线图的范围就是当日电视剧的播出起始时间,通过切换日期可以发现,在没有播出的日期线图没有内容。爬取思路就是遍历日期,然后获取图表的起始时间点。
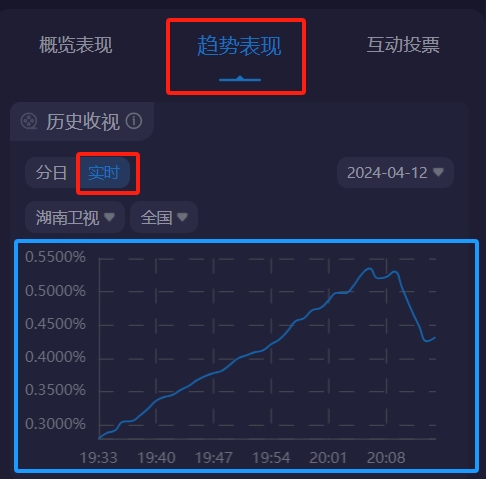
线图一般是通过从后端数据接口获取数据,然后使用JavaScript在网页上绘制出来,因此我们尝试截取数据接口的响应。右键审查元素,切换到Network标签,由于线图是动态生成的,所以我们选择Fetch/XHR类型的响应,然后随意切换一个日期,就可以在看到来自数据接口的响应。
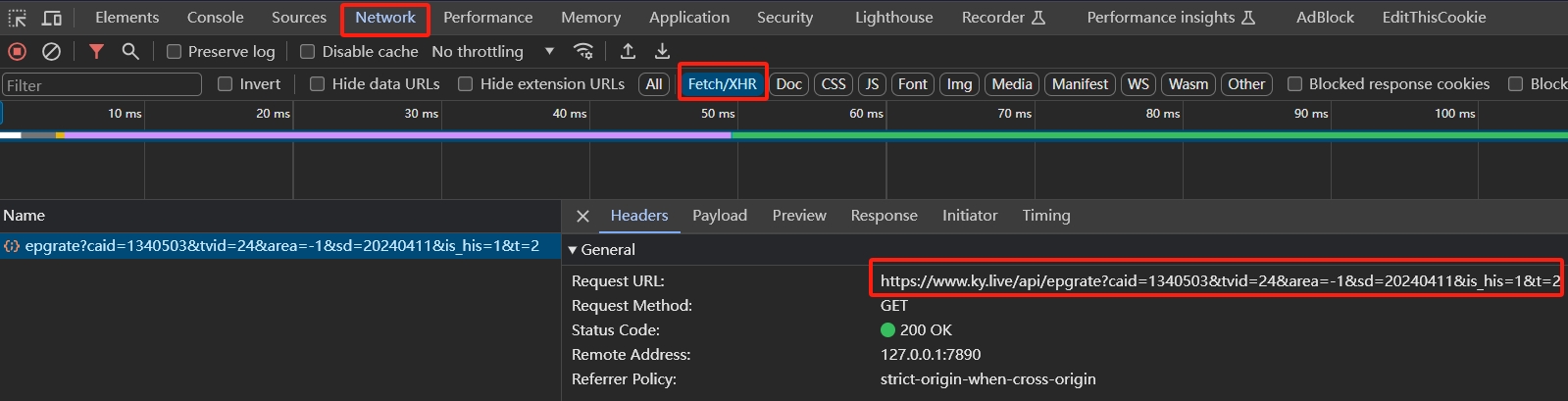
在Headers标签下可以看到数据接口是https://www.ky.live/api/epgrate? 查询是caid=1340503&tvid=24&area=-1&sd=20240411&is_his=1&t=2。其中caid表示电视剧编号,tvid表示电视频道编号,sd表示查询日期,其余参数我们保持原样。
数据爬取
通过编写下面的函数可以完成对数据接口的一次请求:
import urllib
import requests
import json
import time
api = "https://www.ky.live/api/epgrate?"
def get_data(caid, tvid, date, sleep=1):
# 构造查询
query = {"caid": caid, "tvid": tvid,
"area": -1, "sd": date, "is_his": 1, "t": 2}
query = urllib.parse.urlencode(query)
# 构造url
url = api + query
# 请求
r = requests.get(url)
if r.status_code != 200:
raise ValueError
else:
# 将响应结果通过json库解析为字典
data = json.loads(r.text)
time.sleep(sleep)
return data
该函数接收的参数包括caid(节目编号),tvid(频道编号)和date(日期),并用sleep参数设置了请求后的暂停时间,避免在批量请求时触发反爬机制。
然后我们将上述函数进行封装,从而对某个日期范围进行批量请求:
# from tqdm.notebook import tqdm # jupyter notebook下导入tqdm
from tqdm import tqdm # 其他IDE下导入tqdm
import pandas as pd
def get_range_data(start, end, caid, tvid):
date_range = pd.date_range(start, end)
date_range = [i.strftime("%Y%m%d") for i in date_range]
results = [get_data(tvid, date) for date in tqdm(date_range)]
return results
这里用到了pandas的date_range函数,可以生成从start到end范围内的所有时间标签。由于数据接口的时间格式要求为20240413,而date_range生成的时间格式为2024-04-13,我们调用strftime方法来转换时间格式。然后循环遍历时间标签,爬取每个时间标签对应的数据。
Tip
这里用到了tqdm库添加进度条,在进行循环时将可迭代对象转换为tqdm对象即可显示进度条,例如:
for i in tqdm(range(10)):
我们设置开始日期为2024-03-18,结束日期为2024-04-12,执行函数,可以看到函数返回了一个包含多个字典的列表:
jsons = get_range_data(start="2024-03-18", end="2024-04-12", caid=1340503, tvid=24)
jsons[0]
# output
[{'status': True,
'message': '',
'data': {'s': '2024-03-18 20:18',
'e': '2024-03-18 21:58',
'w': '周一',
'i': [{'r': 0.004141, 't': '202403182018'},
...
'tvid': 24,
'avg_r': 0.0,
'tvn': '湖南卫视',
'n': '与凤行 1 2'}}
我们编写一个函数,遍历每一天对应的数据,对内容进行整理。我们需要的数据在字典的data键下,键s,e,tvn, n对应的值分别为播出时间,结束时间,频道和集数。
def parse_jsons(jsons):
for json in jsons:
data = json["data"]
data = {k:v for k,v in data.items()
if k in ["s", "e", "tvn", "n"]}
yield data
Tip
上述函数的yield表示这个函数返回一个generator,我们可以通过list将其序列化变成一个列表
最后我们可以将整理好的数据转换成DataFrame:
pd.DataFrame(list(parse_jsons(jsons)))
# output
s e tvn n
0 2024-03-18 20:18 2024-03-18 21:58 湖南卫视 与凤行 1 2
1 2024-03-19 20:21 2024-03-19 21:59 湖南卫视 与凤行 3 4
2 2024-03-20 20:18 2024-03-20 21:59 湖南卫视 与凤行 5 6
3 2024-03-21 20:27 2024-03-21 22:05 湖南卫视 与凤行 7 8
4 2024-03-22 19:54 2024-03-22 20:23 湖南卫视 与凤行 9
5 2024-03-23 19:53 2024-03-23 20:24 湖南卫视 与凤行 10
...