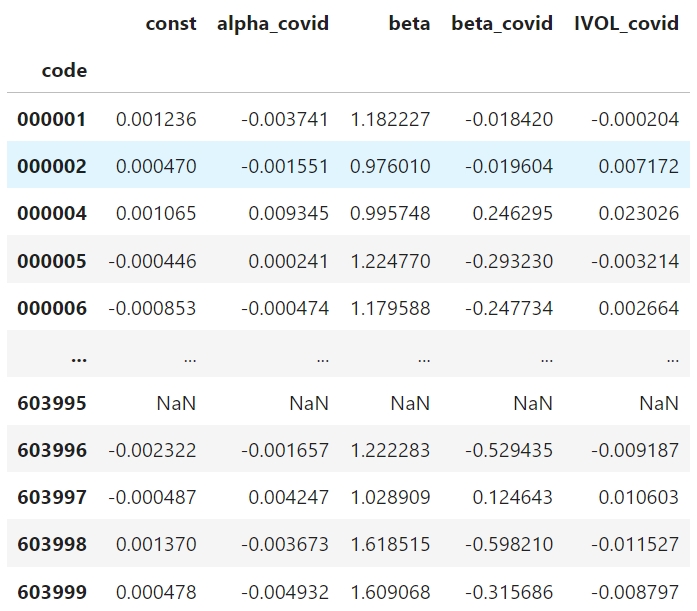
估计COVID-19超额风险和超常收益率
在 Systematic COVID risk, idiosyncratic COVID risk and stock returns 这篇论文中,我们使用了基于事件的方法来估计COVID-19爆发期间个股的超额风险和超常收益。 这里对该方法进行详细介绍。
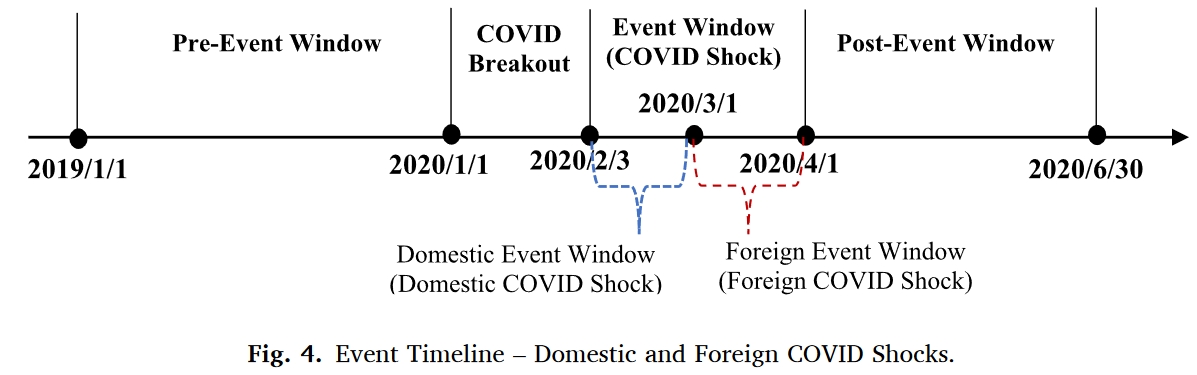
估计思路
我们的估计基于日度数据进行,首先定义如下事件窗口:
| 窗口类型 | 时间区间 | 说明 |
|---|---|---|
| Event window | 2020-02-03 to 2020-03-31 | 该窗口为2020年春节休市结束到3月底市场逐渐稳定的这段时间,期间数据用来捕捉我们关心的超额风险和超常收益。 |
| Estimation window | 2019-01-01 to 2019-12-31 | 该窗口按照未受到事件影响的原则选择了事件前1个季度到事件前1年这段时间,用来捕捉正常情况下的风险和收益情况。 |
然后我们定义虚拟变量\(d\):当观测值处于event window内时,\(d\) = 1;当观测值处于estimation window内时,\(d\) = 0
根据下列模型,使用event window和estimation window内的数据可以估计超额风险和超额收益:
\(R_{i,t}-R_{f,t}=\alpha_i+\alpha_{COVID_i}\times d\ +\ (\beta_i+\beta_{COVID_i}\times d)(R_{m,t}-R_{f,t})+\varepsilon_{i,t}\)
- \(\alpha_{COVID_i}\)度量的是疫情期间经市场模型调整的超常收益率
- \(\beta_{COVID_i}\)度量的是由疫情引起的系统性风险,即个股收益率和市场收益率的超额协方差
- 个股的特质性风险(idiosyncratic risk)通常使用残差的标准差进行估计,这里我们使用event window内残差的标准差减去estimation window内残差的标准差估计由疫情引起的个股特质风险:\(EXIVOL_{COVID}=\hat{\sigma} _{\mu}-\hat{\sigma} _{\theta}\)
Python代码
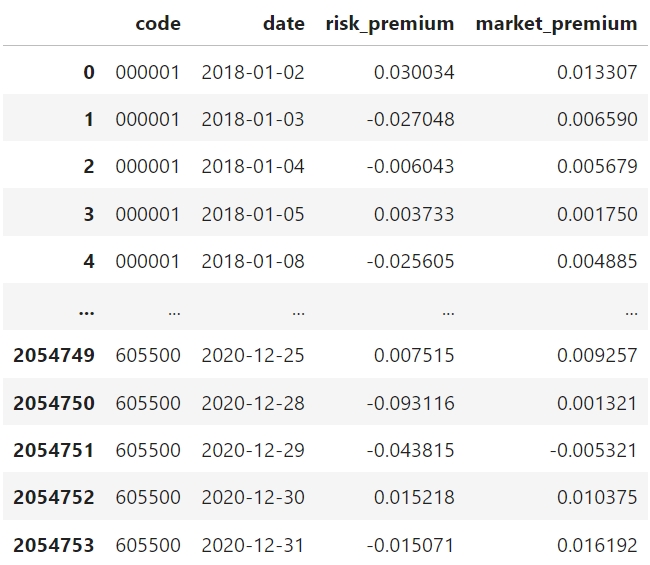
我们需要准备日度个股\(R_{i,t}-R_{f,t}\)(risk premium)数据和\(R_{m,t}-R_{f,t}\)(market premium)数据,类似下表:
全局变量定义event window和estimation window,筛选出窗口内的数据,然后定义虚拟变量\(d\)
event_window = ["2020-02-03", "2020-03-31"]
estimation_window = ["2019-01-01", "2019-12-31"]
data_esti = data.query("(date >= @estimation_window[0] and date <= @estimation_window[1]) or (date >= @event_window[0] and date <= @event_window[1])").copy()
# 判断date是否处在事件窗口,然后转换为整数型就有虚拟变量d:在事件窗口内取1,不在就取0
data_esti["d"] = data_esti.eval("date >= @event_window[0] and date <= @event_window[1]").astype(int)
将估计方法封装到了一个函数内:
函数参数
其中group参数表示单支股票的数据,min_esti_window和min_event_window参数表示对观测值数量进行要求。
# 使用了statsmodels的公式api
import statsmodels.formula.api as smf
def covid_beta_IVOL_estimate(group, min_esti_window, min_event_window):
'''
逐股进行回归,并提取COVID excess beta和IVOL
'''
df = group.copy()
df = df.sort_values("date").set_index("date")
code = df["code"].iloc[0]
'''
如果事件窗口和估计窗口不满足最低要求,则返回空值
'''
# 对事件窗口长度做出限制
if df.eval("d == 1").sum() < min_event_window:
return pd.Series({"const" : np.nan,
"alpha_covid" : np.nan,
"beta" : np.nan,
"beta_covid" : np.nan,
"IVOL_covid" : np.nan})
# 对估计窗口长度做出限制
if df.eval("d == 0").sum() < min_esti_window:
return pd.Series({"const" : np.nan,
"alpha_covid" : np.nan,
"beta" : np.nan,
"beta_covid" : np.nan,
"IVOL_covid" : np.nan})
'''
进行回归
'''
# smf添加交互项时会自动添加单独项,d*market_premium表示 d + market_premium + d*market_premium
model = smf.ols(formula = "risk_premium ~ d*market_premium", data = df, missing = "drop")
res = model.fit()
'''
提取估计系数
'''
const = res.params["Intercept"]
alpha_covid = res.params["d"]
beta = res.params["excess_market_float"]
beta_covid = res.params["d:excess_market_float"]
'''
计算covid excess IVOL
'''
# 估计窗口内的残差
theta = res.resid.loc[estimation_window[0] : estimation_window[1]]
# 事件窗口内的残差
miu = res.resid.loc[event_window[0] : event_window[1]]
# 计算估计窗口内残差的标准差
sigma_theta = np.sqrt(np.mean(np.power(theta, 2)))
# 计算事件窗口内残差的标准差
sigma_miu = np.sqrt(np.mean(np.power(miu,2)))
# 计算covid excess IVOL = sigma_miu - sigma_theta
IVOL_covid = sigma_miu - sigma_theta
return pd.Series({"const" : const,
"alpha_covid" : alpha_covid,
"beta" : beta,
"beta_covid" : beta_covid,
"IVOL_covid" : IVOL_covid})
# 通过使用groupby方法将函数应用到每支股票的数据上,从而得到每支个股的估计值
excess_covid_beta_IVOL = data_esti.groupby("code").progress_apply(covid_beta_IVOL_estimate,
min_esti_window = 180,
min_event_window = 5)
估计结果如下: