复现The Pre-Announcement Drift in China -- Fig 2 & Tab 2
Jun Pan and Qing Peng在 The Pre-Announcement Drift in China: Government Meetings and Macro Announcements 中提出,中国股票市场收益率在重要政府会议前48小时内会显著升高,这表明中国是一个自上而下的经济体,市场受到政策驱动。
在这里,我对论文中的Figure 2和 Table 2进行复现,并提供代码。
Fig 2复现结果:
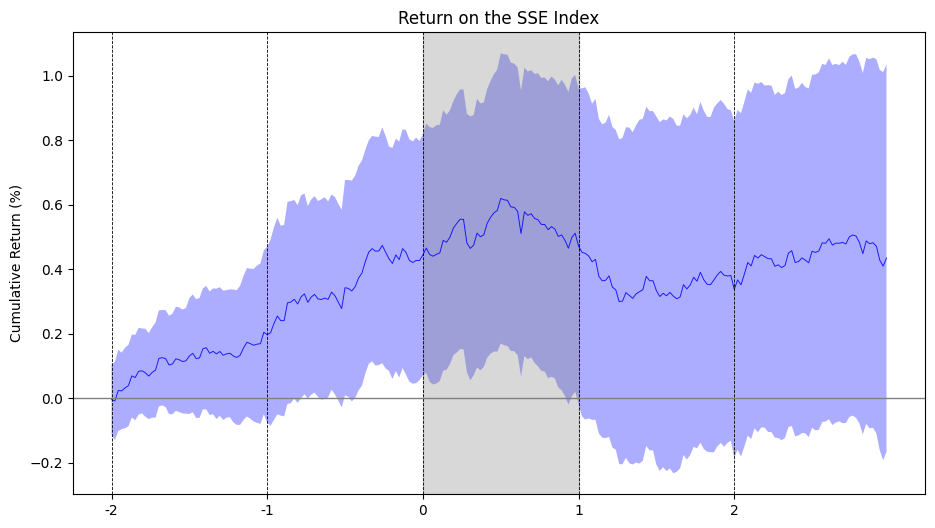
复现结果
Figure 2
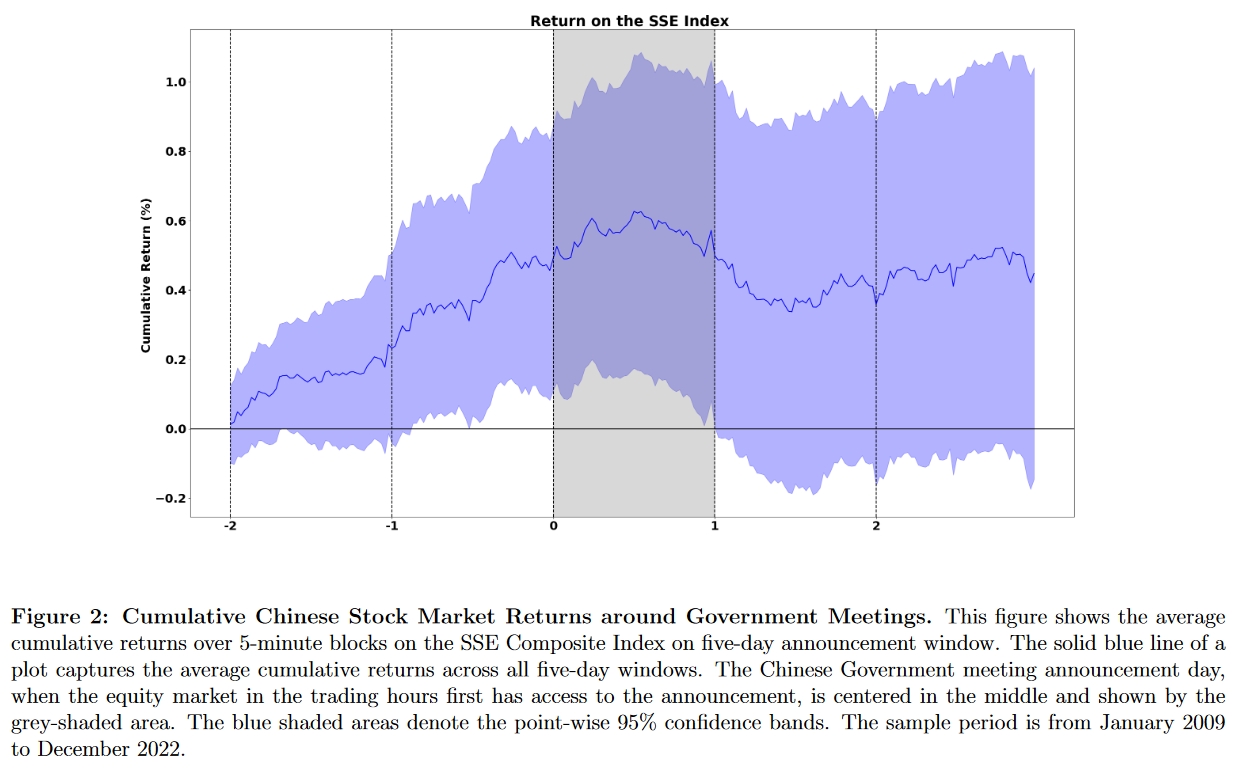
这篇论文整理了2009年到2022年间的95个重要政府会议(包括党的全国代表大会3次、全国两会14次、中央全会19次、中央政治局会议59次), Figure 2中绘制了这95次会议前后共5天窗口内上证指数5分钟高频累计收益率的情况
论文原图:
复现结果:
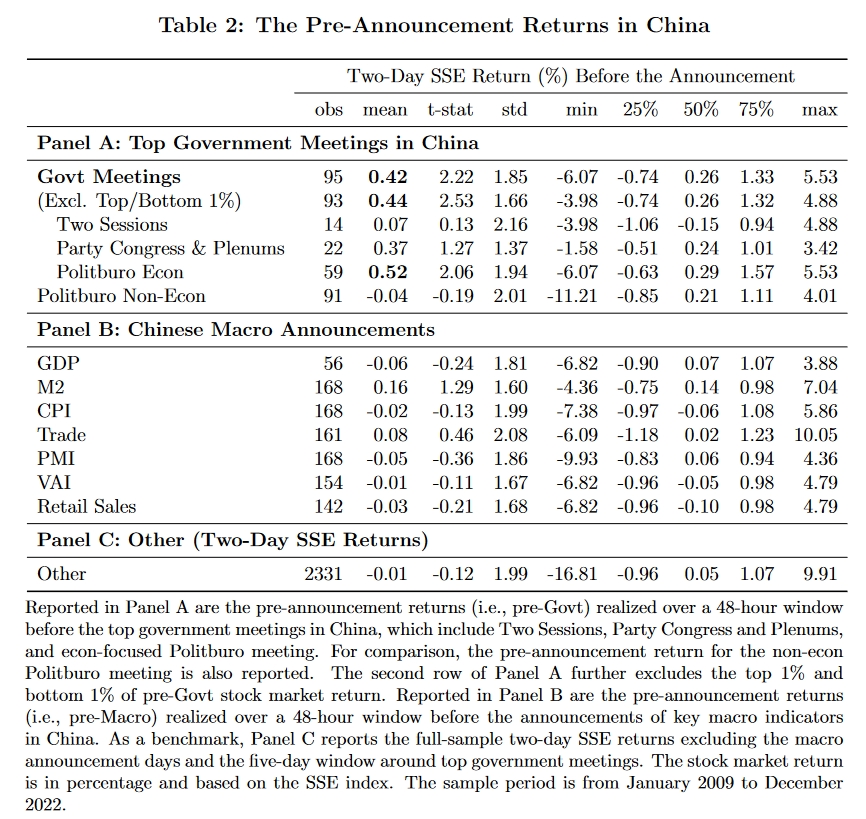
Table 2
Table 2对95次重要政府会议前48小时的上证指数累计收益率情况进行了统计,此外还整理了一系列宏观经济指标发布事件,并统计了前48小时的上证指数累计收益率作为对比
论文原表:
复现结果:
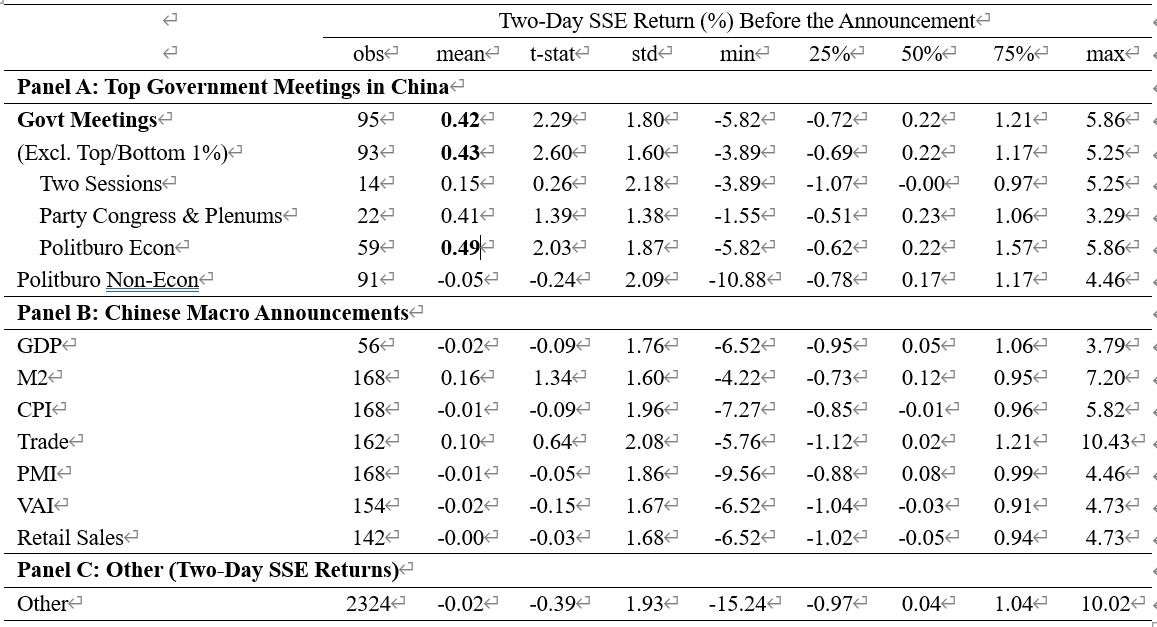
复现细节
数据
- 数据来源:RESSET 高频数据
- 数据清洗:根据原文,分别剔除上午、下午交易时段的前后5分钟(即只取9:35到11:25和13:05到14:55)
- 高频收益率计算:包含隔夜收益率,即每日第1个观测值的收益率=(第1个观测值成交价 – 昨日最后1个观测值成交价) / 昨日最后1个观测值成交价
事件窗口
-
事件日的确定:
- 两会、党的全国代表大会、中央全会:会议日期后推的第1个交易日(如果当日是交易日,则事件日就是当日)。
- 中央政治局会议:会议结束后的第1个交易日(根据原文,会议当日是交易日也不能作为事件日)
- 宏观经济指标发布:发布日后推的第1个交易日(如果当日是交易日,则事件日就是当日)。根据原文,如果15:00以后发布,则当日即使是交易日也不能作为事件日,要后推1天。
-
事件窗口确定规则:
- day 0: 原始事件日如果是交易日就沿用,如果不是则向后找第1个交易日
- day -1: day 0前推1日,如果不是交易日则继续前推
- day -n: 根据day -(n-1)前推1日,如果不是交易日则继续前推
- day +1: day 0后推1日,如果不是交易日则继续后推
- day +n: 根据day +(n-1)后推1日,如果不是交易日则继续后推
其他细节
1. 宏观经济指标事件采用名称匹配的方式从彭博数据中找出,匹配规则如下表所示,得到的事件数目和原文相同:
| 宏观经济指标 | 匹配的正则表达式 |
|---|---|
| GDP | .GDP 同比. |
| M2 | .M2. |
| CPI | .CPI. |
| Trade | ^贸易余额$ |
| PMI | ^制造业采购经理指数$ |
| VAI | .工业增加值年迄今同比. |
| Retail Sales | .社会消费品零售总额同比. |
2. 宏观经济指标发布日中的PMI在2009-01-04有一次发布,因为其事件窗口落到样本区间外,故将该事件剔除。
Python代码
由于数据处理过程较为繁琐,所以在此只附上事件研究和绘图相关代码,感兴趣的读者可以联系我获取完整代码
事件研究代码
下列代码用于计算事件窗口内的累计收益率
def find_nearest_trd_after(date, trd_dates):
'''
该函数用于从指定日期向后寻找最近的一个交易日
如果指定日期是交易日则直接返回
'''
# 计算date和每个交易日的天数间隔
interval = (trd_dates - date).dt.days
# 取出天数间隔不为负的
posi_interval = interval[interval >= 0]
# 返回天数间隔最小的交易日
return trd_dates[posi_interval.idxmin()]
def find_nearest_trd_before(date, trd_dates):
'''
该函数用于从指定日期向前寻找最近的一个交易日
如果指定日期是交易日则直接返回
'''
# 计算date和每个交易日的天数间隔
interval = (trd_dates - date).dt.days
# 取出天数间隔不为正的
negative_interval = interval[interval <= 0]
# 返回天数间隔最大的交易日
return trd_dates[negative_interval.idxmax()]
def get_post_window(day0, n, trd_dates):
'''
该函数传入day0,推出day 1,..,day n
'''
post_window = {}
base = day0 # 参考点设置为day0,从day0开始偏移
for d in range(1, n+1):
next_day = base + pd.offsets.Day(1) # 参考点后推一天
base = find_nearest_trd_after(next_day, trd_dates) # 找到后推一天向后的最近一个交易日
post_window[d] = base # 赋值
return post_window
def get_pre_window(day0, n, trd_dates):
'''
该函数传入day0,推出day -1,..,day -n
'''
pre_window = {}
base = day0 # 参考点设置为day0,从day0开始偏移
for d in range(1, n+1):
d = -d
previous_day = base - pd.offsets.Day(1) # 参考点前推一天
base = find_nearest_trd_before(previous_day, trd_dates) # 找到前推一天向前的最近一个交易日
pre_window[d] = base # 赋值
return pre_window
def get_event_window(event_date, n, trd_dates, only_pre=False):
'''
该函数整合了前面的函数
传入event_date,找到day0,以及长度为n的event_window
'''
day0 = find_nearest_trd_after(event_date, trd_dates) # 从event_date向后找最近的交易日作为day0
pre_window = get_pre_window(day0, n, trd_dates)
if not only_pre:
post_window = get_post_window(day0, n, trd_dates)
event_window = post_window | pre_window # 取并集
else:
event_window = pre_window
event_window[0] = day0
# 根据day排序
kvs = list(event_window.items())
kvs = sorted(kvs, key=lambda x: x[0])
event_window = {k:v for k,v in kvs}
return event_window
def single_window_data(event_date, n, trd_dates, data, id_,
data_ret="ret1_f", data_date="date", data_time="time",
only_pre=False):
'''
该函数从给定的日期计算事件窗口
然后从总数据中提取出每个事件日的数据
'''
event_window = get_event_window(event_date, n, trd_dates, only_pre=only_pre)
event_data = index_data[index_data[data_date].isin(event_window.values())].copy()
# 添加属于第几个窗口的信息
dt2window = {v: k for k,v in event_window.items()}
event_data["window"] = event_data[data_date].map(dt2window) # 注意列名date
# 计算累计收益率cumprod
event_data["cum_ret"] = (event_data[data_ret] + 1).cumprod() - 1
# 整理
event_data = event_data.reindex(columns=[data_date, "window", data_time, "cum_ret", data_ret])
event_data["event_id"] = id_
return event_data
def all_window_data(all_event_date, n, trd_dates, data,
data_ret="ret1_f", data_date="date", data_time="time",
only_pre=False):
'''
该函数对上面的函数进一步封装
传入日期序列,从总数据中提取出每个日期对应的全部事件日的数据
'''
data_ls = []
for id_, event_date in enumerate(tqdm(all_event_date, desc="Gathering window data")):
df = single_window_data(event_date, n, trd_dates, data, id_,
data_ret, data_date, data_time,
only_pre=only_pre)
data_ls.append(df)
return pd.concat(data_ls)
下面的代码用于计算平均累计收益率和置信区间
def get_ci(series, confidence=0.95):
'''
该函数用于计算一组数据的均值和置信区间
'''
res = sm.OLS(series, np.ones_like(series)).fit()
ci = res.conf_int().values[0]
mean = res.params.iloc[0]
return pd.Series({"mean": mean, "l_ci": ci[0], "u_ci": ci[1]})
绘图代码
下面的代码为Figure 2的绘图代码,根据下列绘图参数能够绘制出除字体外与原图完全相同样式的图片
def plot_agg_mean(agg_mean):
fig, ax = plt.subplots(1, 1)
fig.set_size_inches(11, 6)
# range作为x坐标
xdata = np.arange(agg_mean.shape[0])
# 获取每个窗口的开头的x坐标
ori_indexs = agg_mean.groupby("window").apply(lambda x: x.index)
xticks = [i[0] for i in ori_indexs]
# 绘制均值
ax.plot(xdata, agg_mean["mean"], color="blue", lw=0.7, alpha=0.85)
# 填充置信区间
ax.fill_between(xdata, agg_mean["l_ci"], agg_mean["u_ci"],
alpha=0.32, color="blue", edgecolor="none")
# 填充day 0
start, end = ori_indexs.loc[0][0], ori_indexs.loc[1][0] # 识别day0的起始和结束
ax.axvspan(start, end, color="grey", alpha=0.3)
# 设置x轴标签
ax.set_xticks(xticks)
ax.set_xticklabels(ori_indexs.index)
# 设置垂直线标识窗口
for x in xticks:
ax.axvline(x, color="black", ls="--", lw=0.6)
# 设置水平线标识0
ax.axhline(0, color="grey", lw=1)
# 设置纵轴名称
ax.set_ylabel("Cumulative Return (%)")
# 设置图标题
ax.set_title("Return on the SSE Index")