基于BERT大语言模型的启发式分词方法
在经济政策不确定性与企业数据资产配置这篇论文中, 我们使用基于BERT大语言模型的方法,对研究报告和政策文件进行启发式分词, 然后筛选出与数据资产相关的术语,从而构建了一个数据资产术语词典。 现在对基于BERT的启发式分词方法进行介绍。
模型选择
构建词典需要先对原始语料进行分词,然后再从词语中分类出相关术语。 由于数据科学发展迅速,可以预见数据资产相关术语有很大比例是新出现的词汇, 传统的基于预设词典的分词方法(例如jieba)难以正确地将这些新词分离出来。
因此我们诉诸于经过海量语料预训练而得到的大语言模型, 我们选择了其中知名度高、开源免费且模型参数量适中(计算资源需求适中)的BERT模型。
具体而言,我们使用的是FacebookAI团队Conneau et al. (2019)(1) 所发布的多语言版本BERT模型,这是该模型的 Hugging Face项目地址 。
- Conneau, A., Khandelwal, K., Goyal, N., Chaudhary, V., Wenzek, G., Guzmán, F., Grave, E., Ott, M., Zettlemoyer, L., Stoyanov, V., 2019. Unsupervised cross-lingual representation learning at scale. arXiv preprint arXiv:1911.02116.
基本思路
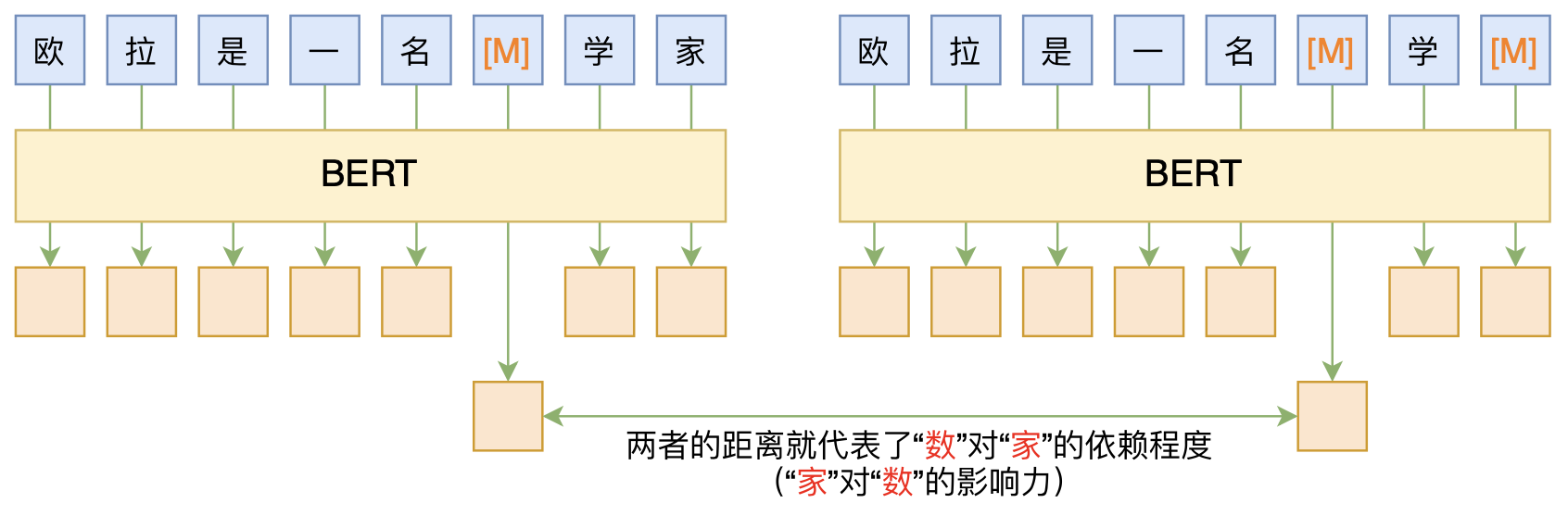
分词的逻辑是判断两个汉字之间的依赖程度, 如果依赖程度低于设定的阈值就可以确定为分词点。 BERT模型的两大优良性质就使其特别适合用来构建启发式分词工具:
- 处理中文的基本单位是单个汉字
- 基于Masked Language Modeling进行训练(1)
- Masked Language Modeling指的是对于每段输入文本, 随机遮盖其中一定比例的汉字,让模型预测被遮盖的部分,从而提取文本中的抽象特征。
根据上述性质,先遮盖文本中的第i个汉字, 经过BERT模型的推断流程将第i个汉字编码为向量A(即隐藏状态,包含了上下文的抽象特征)。 然后同时遮盖文本中的第i个和第j个汉字, 经BERT模型再次将第i个汉字编码为向量B。 由于向量B相对于向量A缺少了汉字j包含的上下文信息, 因此向量B和向量A之间的距离就代表着汉字i对汉字j的依赖程度。
在实际构建分词器的过程当中,拿到一段文本后需要遍历文本中的每一个汉字, 然后根据上述步骤判断该汉字对下一个汉字的依赖程度,最后基于设定的阈值决定是否分词。
Python代码
首先导入需要的库并加载模型,需要安装pytorch和hugging face的transformers库:
import torch
from transformers import AutoTokenizer, AutoModel
import collections
import jieba
import os
import re
import glob
import json
from tqdm.notebook import tqdm
tqdm.pandas(desc = "bar")
os.environ["http_proxy"] = "http://127.0.0.1:7890"
os.environ["https_proxy"] = "http://127.0.0.1:7890"
device = "cuda" if torch.cuda.is_available() else "cpu"
# 在线或从本地缓存加载模型和权重
checkpoint = "xlm-roberta-base"
model = AutoModel.from_pretrained(checkpoint)
model.to(device)
model.eval()
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
Warning
国内可能无法直接访问Hugging Face主站及其资源
根据之前介绍的思路编写分词器,向量距离的度量我选择了最简单的欧氏距离:
# 采用欧几里得距离
def dist(x, y):
return torch.sqrt(((x - y)**2).sum())
# 该函数用于中文汉字
def get_pure_CH_text(string):
pattern = '[\u4e00-\u9fa5]+'
pure_text_ls = re.findall(pattern, string)
return pure_text_ls
# 导入停用词表
with open("./补充材料/中文停用词表/cn_stopwords.txt", "r", encoding = "utf-8") as f:
stop_words = f.readlines()
stop_words = [i.replace("\n", "") for i in stop_words] + ["▁"]
# 根据停用词表剔除停用词
def remove_stop_words(string):
tokens = list(jieba.cut(string))
return "".join([t for t in tokens if t not in stop_words])
# 构建分词器
def LLMtokenizer(string, threshold):
# 将文本tokenization转换为适合模型的输入
input_ids, attention_mask = tokenizer(string).values()
'''
把input_ids重复2*序列长度 - 1次,构建一个tensor
其中偶数行用于每次mask第i个token,奇数行用于每次mask第i和第i+1个共两个token
所以偶数行有length次重复,而奇数行只有length - 1次重复
'''
length = len(input_ids) - 2 # 去掉首尾的特殊标记后剩余长度
batch_token_ids = torch.tensor([input_ids] * (2 * length - 1), dtype = torch.long)
batch_attention_mask = torch.ones_like(batch_token_ids)
'''
逐个对重复的input_ids进行mask
先mask第2个token(第一个token为特殊标记),放在0行
然后mask第3个token,放在2行;mask第3个和第2个token
偶数行mask第i个token,紧接着的奇数行mask第i和第i-1个token
由于循环length次,length为全长-2,不会遍历到最后一个特殊标记
'''
for i in range(length):
# 从第2个字开始mask,放在偶数行(从0行开始)
batch_token_ids[2*i, i+1] = tokenizer.mask_token_id
if i > 0:
# mask第i+1个字及其前一个字
batch_token_ids[2*i-1, i] = tokenizer.mask_token_id
batch_token_ids[2*i-1, i+1] = tokenizer.mask_token_id
'''
将mask好的batch传入模型
'''
batch_token_ids = batch_token_ids.to(device)
batch_attention_mask = batch_attention_mask.to(device)
with torch.no_grad():
out = model(input_ids = batch_token_ids, attention_mask = batch_attention_mask)
hidden_states = out["last_hidden_state"].detach()
'''
先将第一个字放入列表中,遍历length - 1次
'''
word_token_ls = [[input_ids[1]]]
for i in range(1,length):
# 计算mask第i个字与同时mask第i个和第i+1个的距离
d1 = dist(hidden_states[2*i-2, i], hidden_states[2*i-1, i])
# 计算mask第i+1个字与同时mask第i个和第i+1个的距离
d2 = dist(hidden_states[2*i, i+1], hidden_states[2*i-1, i+1])
d = (d1+d2)/2
if d >= threshold:
word_token_ls[-1].append(input_ids[i+1])
else:
word_token_ls.append([input_ids[i+1]])
llm_res = ["".join(tokenizer.convert_ids_to_tokens(i)) for i in word_token_ls]
return llm_res
最后使用分词器对语料库进行批量处理, 这里略去了从PDF中提取文本的过程,感兴趣的读者可以自行研究或联系我获取代码:
'''
下面用于对整个文件夹下的所有txt文件里的长句子进行分词
每个文件全部分词完毕后保存为一个json
'''
# 保存路径
json_save_path = "./长句子分词结果/政策报告和政策文件/"
# 要尝试的分词阈值
threshold_ls = [1.5, 2, 2.5]
# 进入词典的最小词长度
min_word_length = 2
pattern = "./PDF提取文本/研究报告和政策文件/long/*.txt"
txt_file_ls = glob.glob(pattern)
for txt in txt_file_ls:
# 要保存的json文件名称
json_file_name = txt.split("\\")[-1].replace(".txt", ".json")
print(json_file_name)
# 检查目标目录是否已经存在该文件,如果是则跳过
if os.path.exists(json_save_path + json_file_name):
print("Pass!")
continue
# 每个文件处理完成后都是一个字典,键为阈值,值为词频counter
file_res = {threshold:collections.Counter() for threshold in threshold_ls}
with open(txt, "r", encoding = "utf-8") as txt_io:
sentences = txt_io.readlines()
sentences = [i.replace("\n", "") for i in sentences] # 去掉每个句子之后的换行符
for string in tqdm(sentences): # 逐个句子处理
for threshold in threshold_ls: # 逐个分词阈值进行分词
tokens = LLMtokenizer(string, threshold)
# 对tokens进行过滤,提取纯中文文本,且长度大于最小词长度
ch_tokens = [ch_token for t in tokens for ch_token in get_pure_CH_text(t) if len(ch_token) >= min_word_length]
# 去除每个分词中的停用词
ch_tokens = [remove_stop_words(i) for i in ch_tokens]
# 添加结果
file_res[threshold].update(ch_tokens)
# 保存单个文件的分词结果
json_res = {k:dict(v) for k,v in file_res.items()}
with open(json_save_path + json_file_name, "w") as js_f:
json.dump(json_res, js_f)