我开发的Python包——Portfolio Sorting排序法
我开发了一个Python包,叫做py_empirical_fin, 这是PyPi项目地址 。我希望能够通过这个包,以简单几行代码就能实现常用的实证分析技术。据我所知,Python中还没有较为完善的用于实证资产定价研究的包。
在这篇文章中,我将介绍这个包的第一个模块sorting,该模块用于实现Portfolio Sorting也就是排序法。 主要功能包括独立和序贯排序,支持计算任意因子模型的alpha,能够以美观的HTML表格输出结果,并且提供将结果导出到word的功能。
输出效果:

使用示例
下面是使用sorting模块,根据公司特征FC1和公司特征FC2的双变量序贯排序代码,整个流程只需要3行代码:
from empiricalfin import sorting
ds = sorting.DoubleSorting(data=data, sortbys=["FC1", "FC2"],
nqs=[5, 5], date="month", ret="ret",
mkt_cap="SIZE")
result = ds.sequential(vw=False)
result.summary(rf_df=rf_df, rf="rf",
alpha_models=[ff3], output_path="./output.docx")
接下来我会详细介绍使用方法
安装
由于我已经将项目上传到了PyPi,因此你可以直接使用pip命令安装py_empirical_fin:
在python中使用如下代码导入sorting模块:
Warning
注意,导入时请使用名称empiricalfin,与项目名称py_empirical_fin不同
Warning
目前,py_empirical_fin只支持在jupyter notebook, jupyter lab或jupyter hub环境中使用, 因为结果输出使用到了jupyter的HTML渲染功能
sorting模块
sorting模块专门用于进行排序分析,目前版本支持最常用的双变量排序法
排序法介绍
姜近勇和潘冠中在《金融计量学》p43 3.2排序分析中对排序法进行了如下阐述:
- 资产组合构造期:利用t-1期的公司特征将所有股票从低到高排序。 按照排序将所有股票分配到不同的序位中去,最高序位的股票具有最高的公司特征值, 中间位股票的公司特征值次之,以此类推。
- 投资组合持有期:计算各序位股票组成的投资组合在t期的收益率
- 统计检验: 检验最高序位和最低序位之间的平均收益率之差。
如果公司特征能够解释期望收益率的变化,那么平均收益率应该随着公司特征的值上升而增大, 也就是随投资组合序位的增大而增大。
样例数据
现在我们以下列样例数据展示sorting模块的功能:
| code | month | ret | FC1 | FC2 | SIZE | |
|---|---|---|---|---|---|---|
| 0 | 000001 | 2000-01-31 | 0.061891 | 0.004058 | 0.030987 | 1.87E+10 |
| 1 | 000001 | 2000-03-31 | 0.00273 | 0.017191 | 0.099298 | 1.96E+10 |
| 2 | 000001 | 2000-04-30 | 0.037016 | 0.014715 | 0.072115 | 1.97E+10 |
| ... | ... | ... | ... | ... | ... | ... |
| 560038 | 605599 | 2023-11-30 | -0.02672 | 0.0051 | 0.067961 | 8.13E+09 |
| 560039 | 605599 | 2023-12-31 | 0.104601 | 0.002854 | 0.033507 | 7.91E+09 |
这是一份A股2000-01到2023-12的月度数据,每个字段的含义如下:
| 字段 | 含义 |
|---|---|
| code | 股票代码 |
| month | 月份 |
| ret | 简单收益率,以小数表示,不能是百分比 |
| FC1 | 公司特征1 |
| FC2 | 公司特征2 |
| SIZE | 公司市值 |
创建DoubleSorting实例
现在我们希望根据FC1和FC2进行双变量排序,首先需要创建sorting模块下的DoubleSorting对象实例, DoubleSorting对象的构造函数共有6个参数:
| 参数 | 含义 |
|---|---|
| data | 排序法所需数据,需要为DataFrame对象 |
| sortbys | 排序依据,包含公司特征1和公司特征2所在列名称的列表 |
| nqs | 分组数量,用列表传入两个公司特征分别对应的分组数量 |
| date | 数据中日期列的名称 |
| ret | 数据中收益率列的名称 |
| mkt_cap | 数据中市值所在列的名称 |
假设我们的数据变量名是data,我们要根据FC1和FC2进行双变量的5组\(\times\)5组的排序, 可以根据下列代码创建DoubleSorting实例对象:
# 创建DoubleSoring对象实例
ds = sorting.DoubleSorting(data=data, sortbys=["FC1", "FC2"],
nqs=[5, 5], date="month", ret="ret",
mkt_cap="SIZE")
计算排序结果
我们可以选择序贯排序和独立排序两种排序方法, 所谓序贯排序就是根据FC1排序后,在每个组内再次根据FC2排序,这样最终得到的25个组合的股票数量相等。
而独立排序就是先对全体样本根据FC1排序,然后再对全体样本根据FC2排序, 同时属于FC1排序最小组和FC2排序最小组的股票属于组合(1,1),以此类推得到组合(1,2),(1,3),...,(5,5)。 独立排序得到的25个组合,每个组合内的股票数量不一定相等。
如果我们想执行序贯排序,则调用DoubleSorting实例的sequential方法,独立排序则对应independent方法:
其中参数vw=False表示等权重组合,而vw=True表示市值加权组合。
调用sequential或independent方法后,程序会立即开始进行计算,需要等待片刻, 待计算完成后会返回result对象,里面保存了计算结果。
结果输出
对result对象调用summary方法即可输出结果:
summary方法有4个重要参数:
| 参数 | 含义 |
|---|---|
| rf_df | 无风险收益率数据,需要为DataFrame对象 |
| rf | 数据中无风险收益率的列名 |
| alpha_models | 计算alpha所使用的因子模型数据,以列表传入,每个元素代表一个模型 |
| output_path | 结果导出到word文档的路径 |
其中无风险收益率数据rf_df需要包含两列,日期列和无风险收益率列, 日期列的名称和格式需要与创建DoubleSorting时的日期列名称一致(比如这里都叫month),程序会自动匹配对应日期的无风险收益率:
| month | rf | |
|---|---|---|
| 0 | 1991/12/31 | 0.006092 |
| 1 | 1992/1/31 | 0.006092 |
| ... | ... | ... |
| 382 | 2023/10/31 | 0.001241 |
| 383 | 2023/11/30 | 0.001241 |
| 384 | 2023/12/31 | 0.001241 |
alpha_models中所传入的因子模型数据也需要是DataFrame对象,且日期列的名称也需要和创建DoubleSorting时的日期列名称一致。 例如,这里我想计算Fama-French三因子模型的alpha,那么我就传入如下数据ff3:
| month | mkt_premium | SMB | HML | |
|---|---|---|---|---|
| 0 | 1999/4/30 | -0.035693 | -0.01497 | 0.032332 |
| 1 | 1999/5/31 | 0.109583 | -0.04102 | -0.01723 |
| ... | ... | ... | ... | ... |
| 5285 | 2023/10/31 | -0.029689 | 0.032917 | -0.00698 |
| 5308 | 2023/11/30 | -0.001868 | 0.05796 | -0.00766 |
| 5331 | 2023/12/31 | -0.015345 | 0.000658 | 0.001553 |
Tip
如果不需要计算因子模型的alpha,可以向alpha_models参数传入空列表。
HTML输出结果
调用summary方法后得到的HTML输出如下:
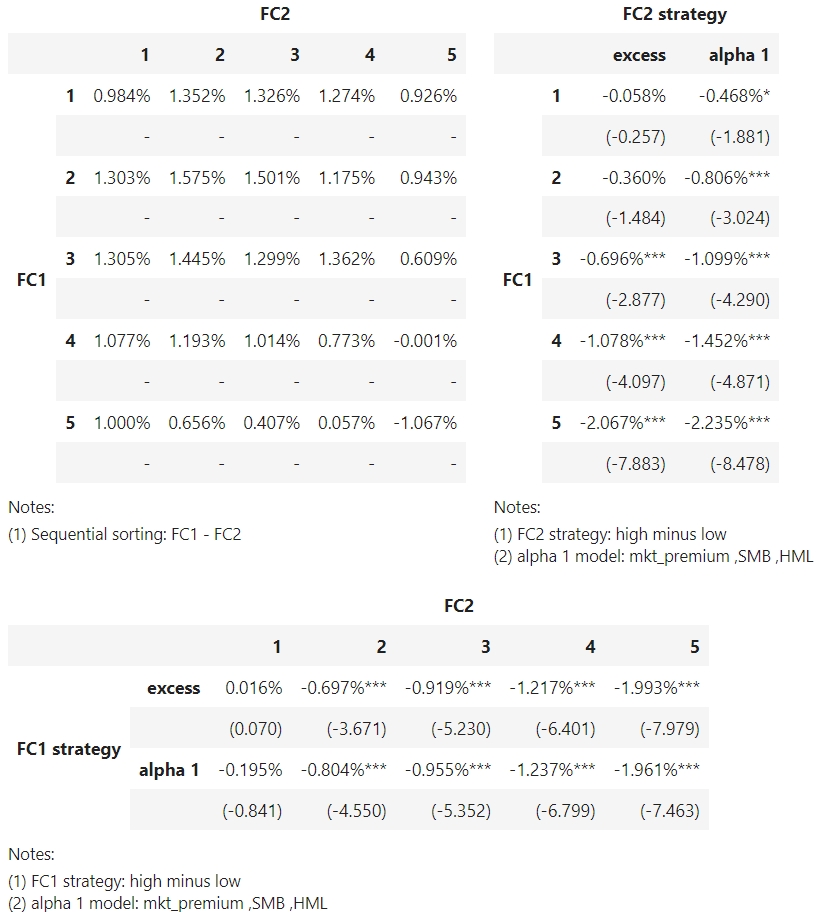
其中,左上角的表格报告了25个组合的平均收益率,右上角的表格报告了每个FC1组合下, FC2最高组与最低组的收益率之差,即FC2 strategy。 下方的表格报告了每个FC2组合下,FC1最高组与最低组的收益率之差,即FC1 strategy。
Warning
t检验使用的均为Newey-West稳健t统计量,目前版本默认最大滞后阶数为5, 未来的版本会添加最大滞后阶数可选项
Word输出结果
下面是Word输出结果
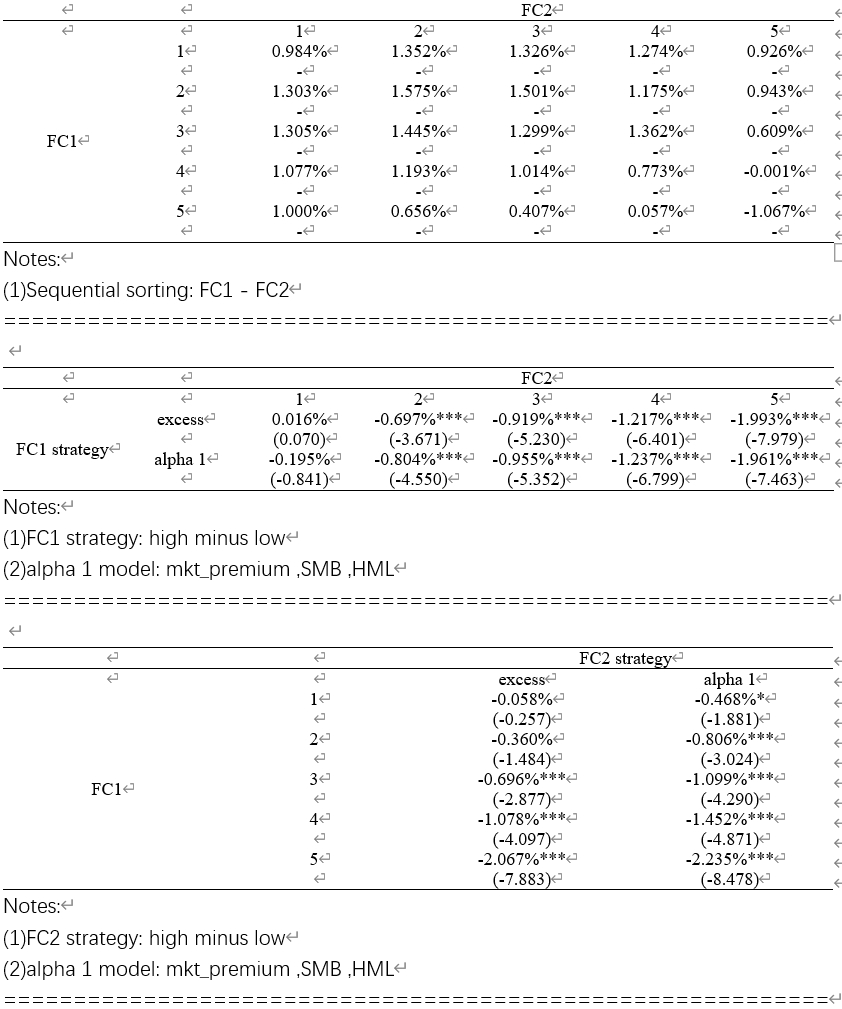
Tip
如果output_path参数传入None,则不进行Word输出
其他参数
summary方法还有一些其他可选参数,可以根据需要添加:
| 参数 | 含义 |
|---|---|
| strategies | 传入'HML'表示计算strategy时使用特征最高组减去特征最低组,如果传入'LMH'则相反 |
| show_t | 是否在左上角的各个组合平均收益率明细表格处显示t值 |
| show_stars | 是否在左上角的各个组合平均收益率明细表格处显示显著性星星 |
| mean_decimal | 平均收益率的小数位数,默认为3 |
| t_decimal | t值得小数位数,默认为3 |
| layout | 结果表格的布局,传入'reverse'可以得到转置后的表格布局 |