基于BERT大语言模型的启发式分词方法
在经济政策不确定性与企业数据资产配置这篇论文中, 我们使用基于BERT大语言模型的方法,对研究报告和政策文件进行启发式分词, 然后筛选出与数据资产相关的术语,从而构建了一个数据资产术语词典。 现在对基于BERT的启发式分词方法进行介绍。
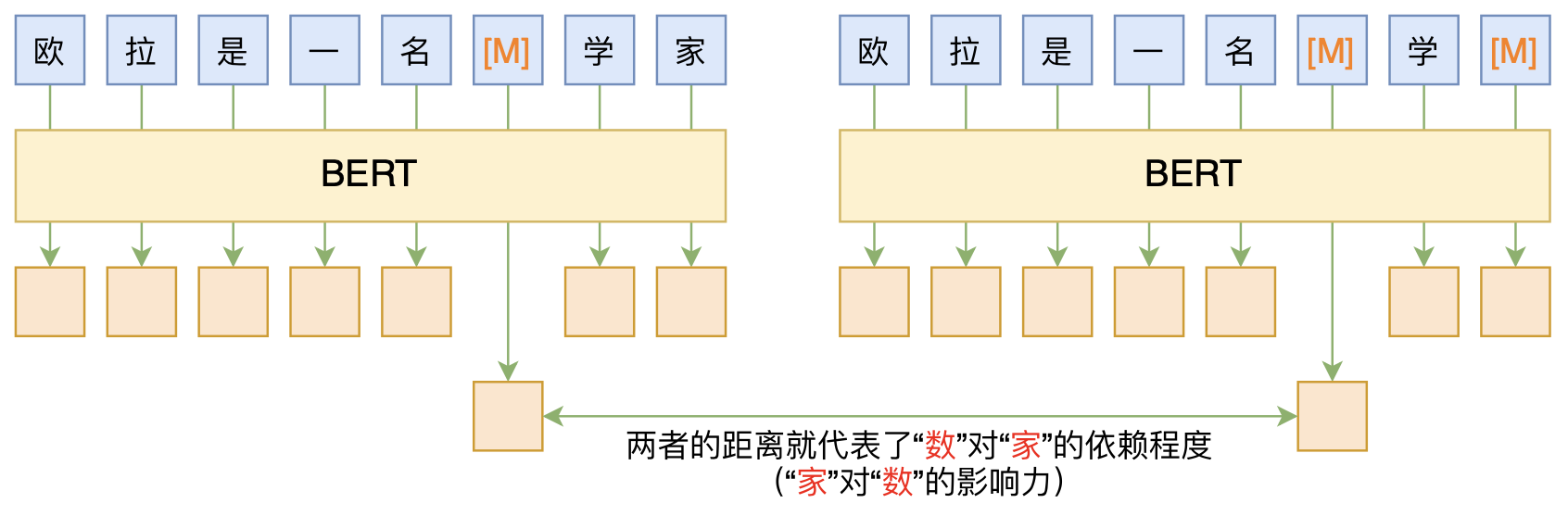
在经济政策不确定性与企业数据资产配置这篇论文中, 我们使用基于BERT大语言模型的方法,对研究报告和政策文件进行启发式分词, 然后筛选出与数据资产相关的术语,从而构建了一个数据资产术语词典。 现在对基于BERT的启发式分词方法进行介绍。
在研究当中可能需要用到公司地址信息,尽管很多数据库都提供这一数据,但其对公司所处行政区划的细分可能不符合我们的要求。例如,我们想获取省、市、区三级行政区划,但CSMAR数据库没有相应的细分数据,只能自行构建。
这篇文章介绍如何部署JavaScript接口,从而在Python中调用接口进行公司地址的智能解析。
graph TD
A(输入:广东省深圳市福田区益田路5023号平安金融中心B座);
A --> B(解析);
B --> C(省份:广东省);
B --> D(城市:深圳市);
B --> E(城区:福田区);
B --> F(邮政编码:440304);
B --> G(...);在管理层回复模板化的股价效应——基于“上证 e 互动”的实证研究这篇论文中, 我们使用利文斯顿编辑距离来度量投资者互动平台上公司管理层回复的模板化程度, 现在对这一方法进行介绍。